
目次
データの可視化
データは,sklearnに入っている「ボストンの住宅価格」のデータセットを使います。
データセットの取得
import pandas as pd
import numpy as np
from sklearn.datasets import fetch_california_housing
import matplotlib.pyplot as plt
import seaborn as sns # データの可視化を行うライブラリ
sns.set() # デフォルトスタイルにseabornを適用
# データの取得
data_house = fetch_california_housing()
data_X = pd.DataFrame(data_house.data, columns=data_house.feature_names)
data_y = pd.Series(data_house.target)
data = data_X.copy()
data["target"] = data_yデータの確認
データの確認には,.info()を使います。
これにより,以下の情報がわかります。
- データの総数
- 特徴量ごとの欠損値の数
- データ型
data_X.info()<class 'pandas.core.frame.DataFrame'> RangeIndex: 20640 entries, 0 to 20639 Data columns (total 8 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 MedInc 20640 non-null float64 1 HouseAge 20640 non-null float64 2 AveRooms 20640 non-null float64 3 AveBedrms 20640 non-null float64 4 Population 20640 non-null float64 5 AveOccup 20640 non-null float64 6 Latitude 20640 non-null float64 7 Longitude 20640 non-null float64 dtypes: float64(8) memory usage: 1.3 MB
統計データの確認
統計データの確認には.describe()を使います。
これにより,以下の情報がわかります。
- 平均値
- 標準偏差
- 最小値・最大値
- 四分位数(25%,50%,75%)
data_X.describe()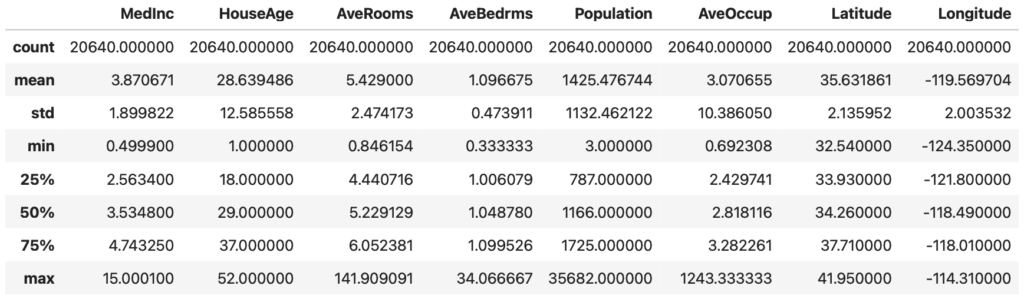
特徴量が多くなることが多いので,転置して表示すると見やすくなります。
data_X.describe().T.round(1)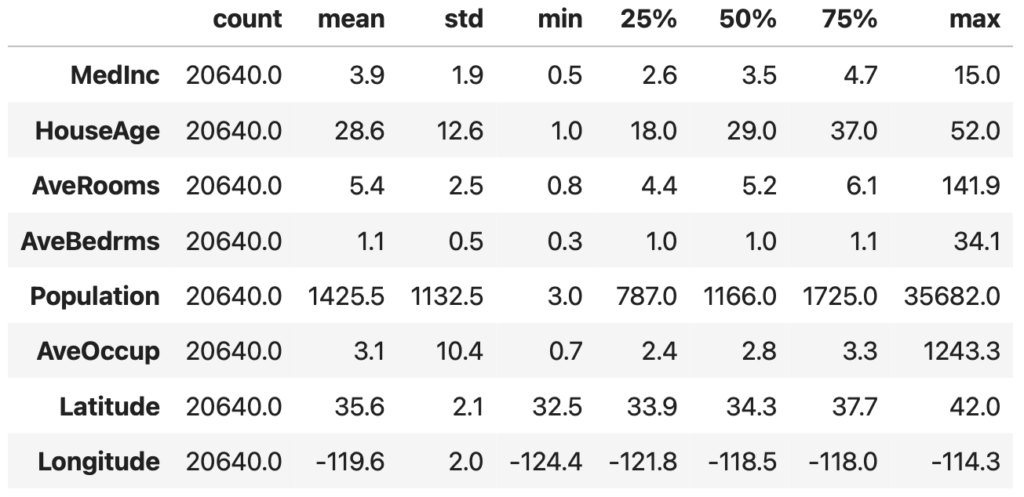
相関係数の確認
各特徴量同士の相関係数の確認には,.corr()を使います。
corr = data_X.corr()
corr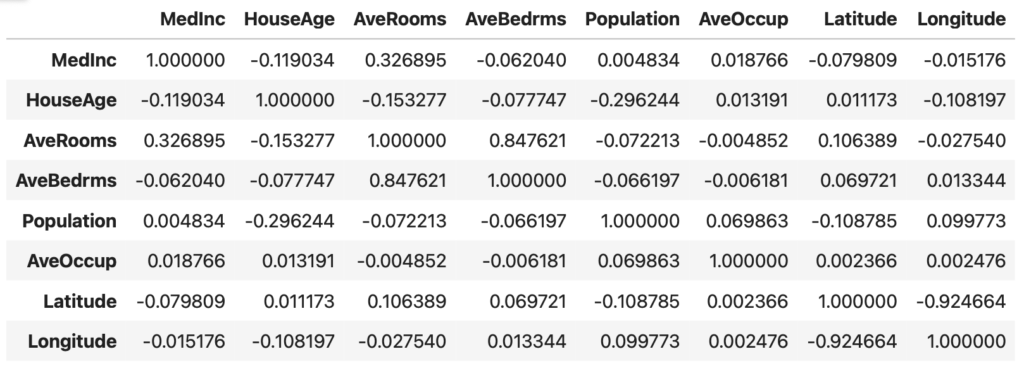
また,数字だけでは分かりにくいので,以下のようにヒートマップで見ることもできます。
ヒートマップ例1
ヒートマップの作成には,seabornのheatmapを使います。
cmap='カラーマップ'とすることで,色を指定することができます。
カラーマップはこちらで確認することができます。
fig = plt.figure(figsize=(10,8))
sns.heatmap(corr, cmap='Blues')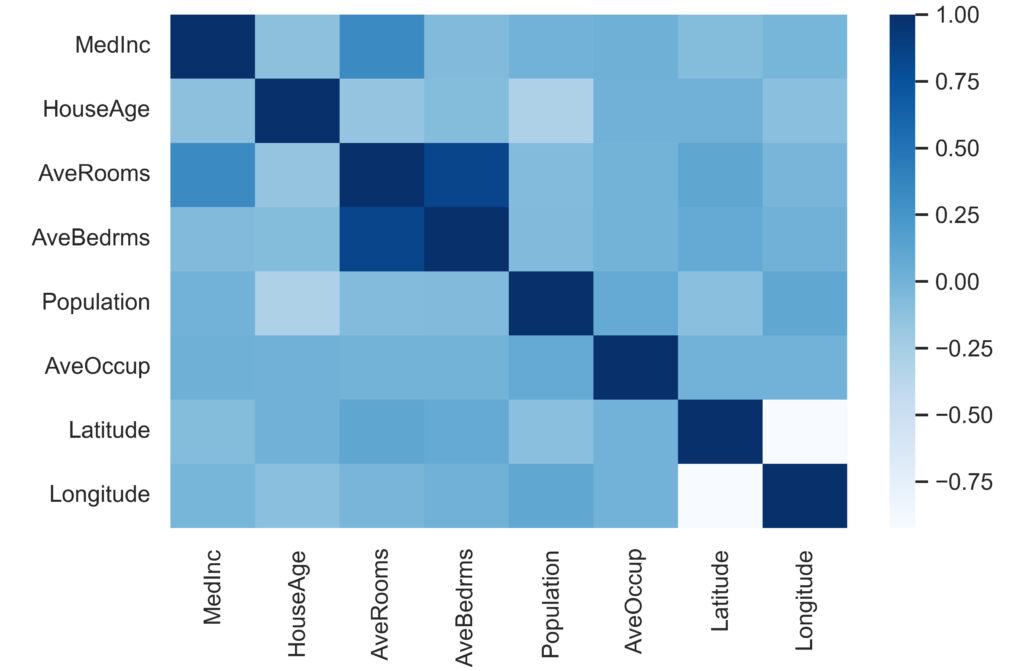
ヒートマップ例2
また,相関係数の値も併せて表示したい場合には,こちらもおすすめです。
corr_cmapという関数に,corrを渡すことで可視化できます。
cmap_color =の部分を変えることで色を変更できます。
from matplotlib.colors import ListedColormap, LinearSegmentedColormap
def corr_cmap(corr):
cmap_color = LinearSegmentedColormap.from_list('orangered', ['#FFECEC','orangered'])
mask = np.zeros_like(corr)
mask[np.triu_indices_from(mask,1)] = True
sns.heatmap(corr, mask=mask, annot=True, cmap=cmap_color, fmt='.2f', linewidths=0.2)
corr_orange_cmap(corr)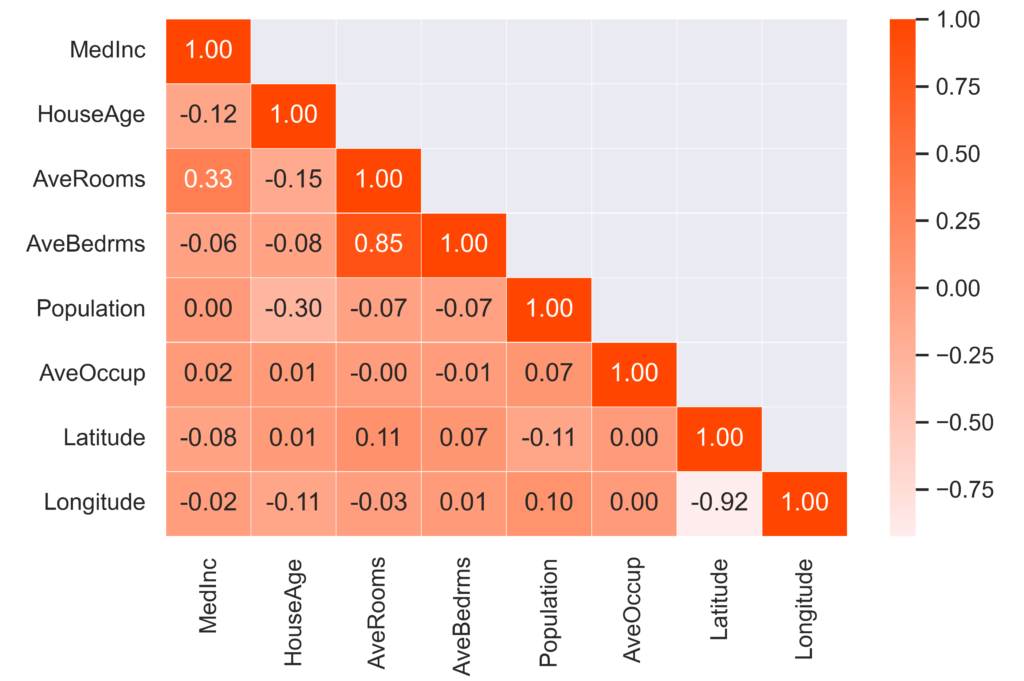
単一特徴量分析
ヒストグラムと平均値を同時に可視化する場合には以下のようにします。
下のグラフは,ヒストグラムを青いビン,平均値を赤い点線で表示できます。
density_visualという関数に,データフレームと表示したいカラム名を渡すことで可視化できます。
def density_visual(df, feature):
plt.figure(figsize=(7, 5),dpi=500)
plt.title("{column_name} Distribution".format(column_name = feature))
sns.histplot(df[feature], stat='density')
sns.kdeplot(df[feature], color='blue')
plt.axvline(df[feature].mean(), color='red', linestyle='--', linewidth=0.8)
min_ylim, max_ylim = plt.ylim()
plt.xlabel(feature)
plt.ylabel("Density")
plt.show()
density_visual(data_X, ”MedInc")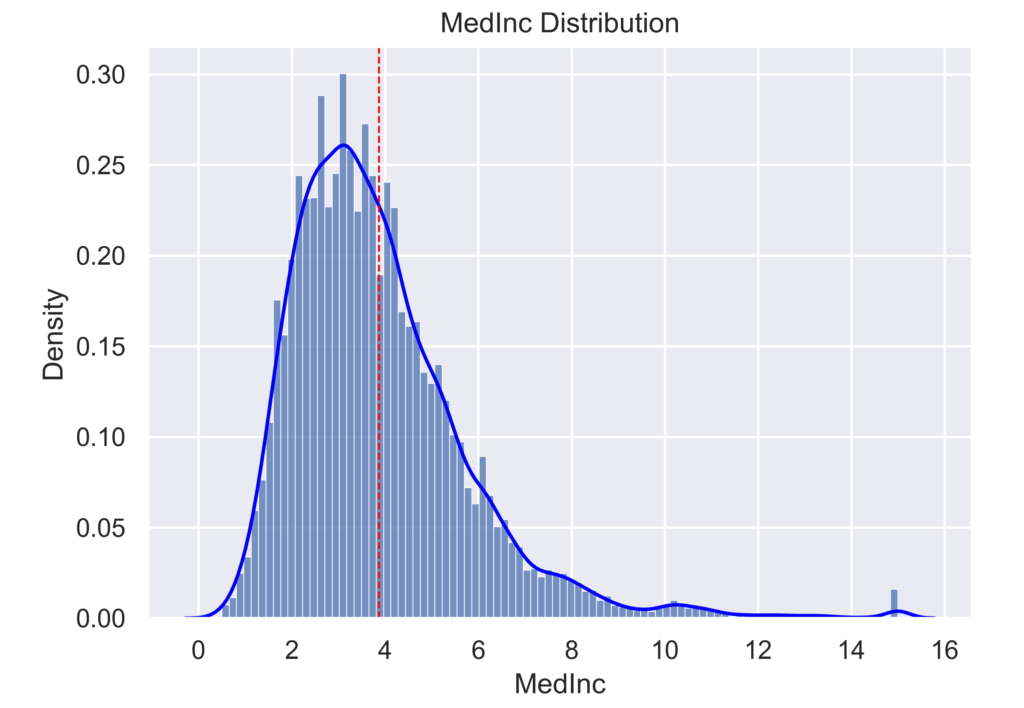
目的変数と説明変数の関係(分類問題の場合)
分類問題の場合は,目的変数と説明変数の関係を可視化することが重要です。
今回は,sklearnのirisデータセットを使用します。
データの取得
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
import matplotlib.pyplot as plt
import seaborn as sns # データの可視化を行うライブラリ
sns.set() # デフォルトスタイルにseabornを適用
# データの取得
data_house = load_iris()
data_X = pd.DataFrame(data_house.data, columns=data_house.feature_names)
data_y = pd.Series(data_house.target)
data_all = data_X
data_all["target"] = data_y
data_all["target_name"] = np.where(data_all["target"] == 0, "setosa", np.where(data_all["target"] == 1, "versicolor", "virginica"))
data_all = data_all.drop("target",axis=1)pairplotによる可視化
pairplot()では,目的変数別に散布図を表示することができます。
対角成分はカーネル密度推定となります。
palette='カラーマップ'とすることで,色を指定することができます。
カラーマップはこちらで確認することができます。
sns.pairplot(data_all, hue='target_name', palette='Purples')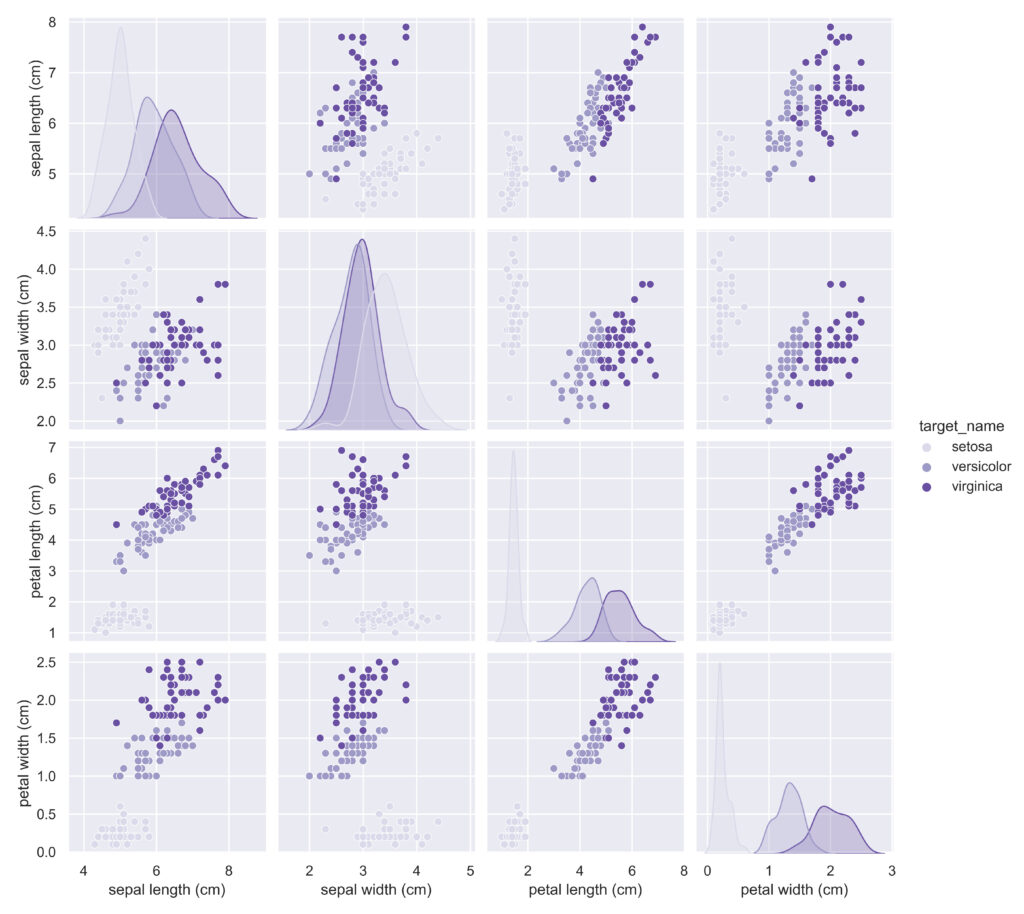

コメント