

- ランダムフォレストの実装方法(ソースコードつき)
- ランダムフォレストでの株価予測の方法
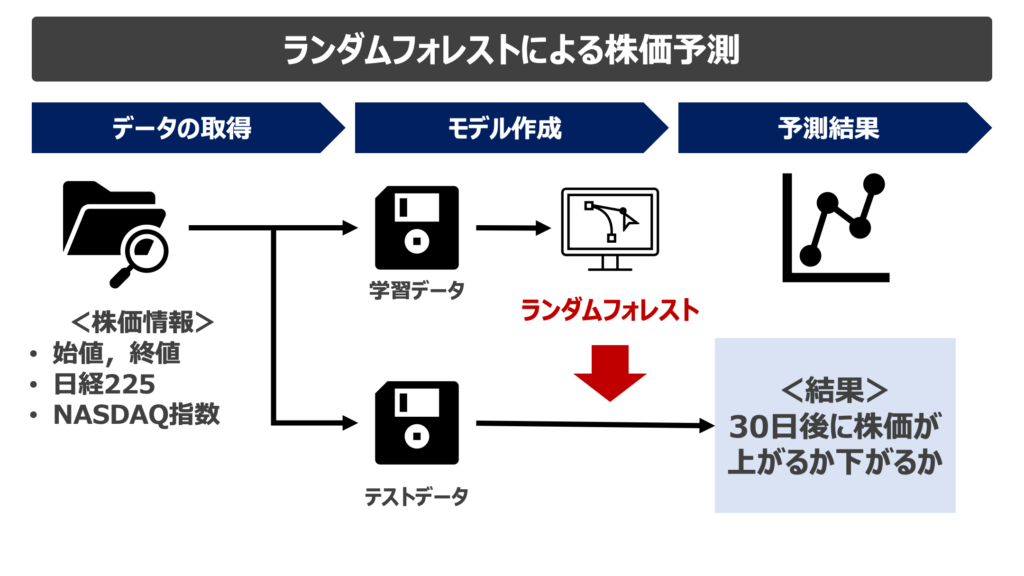
ランダムフォレストによる株価予測の概要
予測は以下の流れで行います。
つまり,30日後に株価が上がるか下がるかを予測する分類モデルになります!
他の手法でも予測しているので,ぜひご覧ください!




事前準備
まずは,環境についてです。
- Python 3.8.15
- macOS Monterey 12.5
必要なライブラリは以下のようになります。ない場合にはpipやcondaで入れてください。
必要なライブラリ
- pandas
- numpy
- sklearn
- datetime
- pandas_datareader
ライブラリのインポート
必要なライブラリのインポートを行います。
import pandas as pd
import numpy as np
from datetime import datetime株価情報の取得
主要な株価指数の取得
予測のための説明変数として,日経平均株価などを取得します。
今回は,日経225,S&P500,ナスダック総合指数を取得しています。
from pandas_datareader import data
marketData = ['NIKKEI225','SP500','NASDAQCOM']
df_market = data.DataReader(marketData,'fred','2014-01-01', '2023-1-31').asfreq("D")
df_market = df_market.fillna(method='ffill')
df_market = df_market.dropna(how='any')3行目:df_market = data.DataReader…
指数を2014年1月1日から2023年1月31日まで取得しています。
4行目:df_market = df_market.fillna…
欠損値を埋めています。
5行目:df_market = df_market.dropna…
欠損値がある場所は削除しています。
株価取得の詳しい内容については以下をご覧ください。

主要な株価指数の前処理
株価指数そのままでは学習しにくいので,移動平均との乖離を計算します。
ここは精度に関係するので試行錯誤する必要があります。
# 各指数の移動平均との乖離率を算出する
for index_name in df_market.columns:
for i in [5,10,30,60,90,120]:
df_market[index_name + "_" + str(i) + "days_diffrol"] =\
(df_market[index_name].rolling(i).mean() - df_market[index_name]) / df_market[index_name].rolling(i).mean()
# 生データは削除する
df_market = df_market.drop(columns=index_name)予測する企業の株価を取得
予測したい企業の株価を取得します。
CODE=の部分は予測したい企業の株価コードを指定します。
今回は4755の企業の予測をしています。
# 予測する企業の株価データを取得
from pandas_datareader.stooq import StooqDailyReader
CODE = 4755
CODE_str = str(CODE) + ".JP"
start = datetime(2014, 1, 1)
end = datetime(2023, 1, 31)
df_target = StooqDailyReader(CODE_str, start=start, end=end).read()
df_target = df_target.sort_values('Date')
df_target = pd.DataFrame(df_target).asfreq("D", method="ffill")5行目:start = datetime(2014, 1, 1)
取得する範囲のスタートを設定します。endも同じです。
8行目:df_target = StooqDailyReader…
データを取得します。
9行目:df_target = df_target.sort_values(‘Date’)
df_targetには最近のデータから順番に入っているので昇順にします。
10行目:df_target = pd.DataFrame…
データの欠損値処理をしています。
予測対象の作成
予測するのは,30日後に株価が上がるか下がるかです。
今回は,今日の終値と30日後の終値を比較して10%以上増加するかしないかを設定しています。
分類問題なので,増加する場合に「1」,それ以外は「0」としています。
# 目的変数の作成(30日後に5 %以上上昇する時に1)
df_target["30days_after"] = df_target["Close"].shift(-30)
df_target['ratio'] = df_target['30days_after'] / df_target["Close"]
df_target['target'] = np.where(df_target['ratio'] > 1.1, 1, 0)
# 不要な行と列を削除
df_target = df_target.dropna(how='any')
df_target = df_target.drop(columns=["ratio","30days_after"])2行目:df_target[“30days_after”] = …
Closeに入っている終値を30日ずらすことで,30日後の終値を取得しています。
3行目:df_target[‘ratio’] = …
30日後の終値を現在の終値で割ることで比を計算しています。
4行目:df_target[‘target’] = …
前述で計算した比率が10%以上増加している場合に「1」,それ以外に「0」をtargetに保存しています。
データの整理
データの結合
これまでに作成したデータを結合して1つのdataframeにします。
# データの結合
df = pd.merge(df_target, df_market, how='left', left_index=True, right_index=True)
df = df.dropna(how='any')学習データとテストデータに分割
今回は,2021年までのデータを使って2022年の予測を行います。
# トレインとテストに分割
df_train = df[:"2021"]
df_test = df["2022":]
# 目的変数と説明変数に分割
X_train = df_train.drop("target", axis=1)
y_train = df_train["target"]
X_test = df_test.drop("target", axis=1)
y_test = df_test["target"]モデルの作成
ランダムフォレストでの学習
いよいよ作成したデータを学習させます。
# 学習
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
model.fit(X_train, y_train) # モデルの学習3行目:model = RandomForestClassifier()
ランダムフォレストの中でも分類器を設定しています。
4行目:model.fit(X_train, y_train)
学習データを入れて学習させます。
結果の保存
予測結果を保存して精度を確認します。
df_resultに結果をまとめます。
# 予測値と実値との比較
df_result = pd.DataFrame()
df_result["Price"] = df_target["Close"]["2022-01-01":]
df_result["true"] = y_test
df_result["Pred"] = model.predict(X_test)5行目:df_result[“Pred”] = model.predict(X_test)
テストデータをモデルに入れた時の結果を保存しています。
結果の確認
混同行列で結果を確認してみましょう。
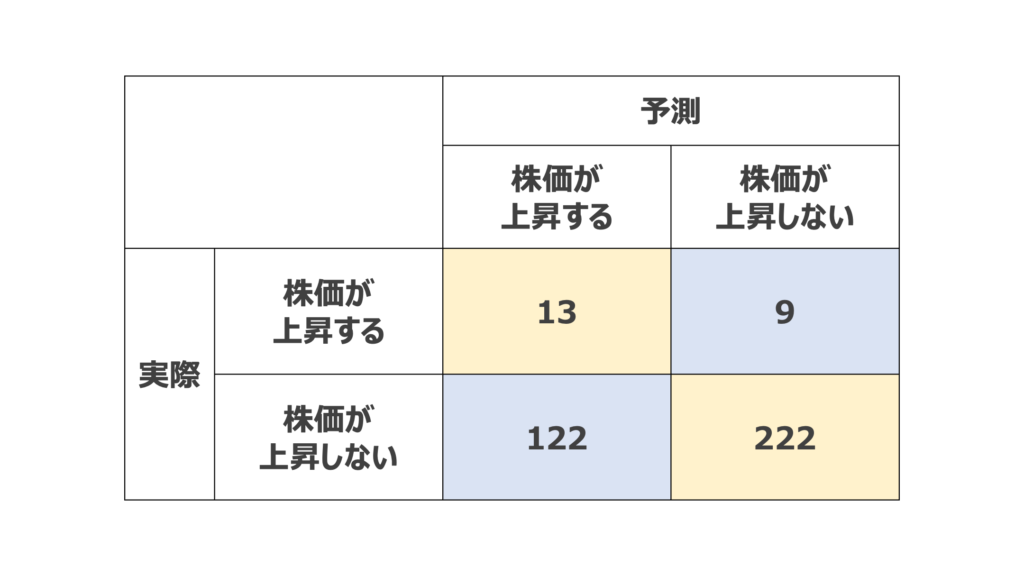
どれだけ正しく分類できたかを表すAccuracyを計算すると,235/366で64%となりました。
まずまずの結果ですが,株を実際に運用する場合には,左下のブロックの「株価が上昇すると予想して外れた場合」を減らす必要があります。
そのためには,以下の方法が考えられます。
精度を上げる方法
- 他のアルゴリズムを使用する
- パラメータチューニングをする
- 他の指標を使って予測する
同じような手法のLightGBMについては,以下の記事で紹介しています!
ソースコードまとめ
今回使用したコードはこちらになります。
import pandas as pd
import numpy as np
from datetime import datetime
# 市場データの取得
from pandas_datareader import data
marketData=['NIKKEI225','SP500','NASDAQCOM']
df_market = data.DataReader(marketData,'fred','2014-01-01', '2023-1-31').asfreq("D")
df_market = df_market.fillna(method='ffill')
df_market = df_market.dropna(how='any')
# 各指数の移動平均との乖離率を算出する
for index_name in df_market.columns:
for i in [5,10,30,60,90,120]:
df_market[index_name + "_" + str(i) + "days_diffrol"] =\
(df_market[index_name].rolling(i).mean() - df_market[index_name]) / df_market[index_name].rolling(i).mean()
# 生データは削除する
df_market = df_market.drop(columns=index_name)
# 予測する企業の株価データを取得
from pandas_datareader.stooq import StooqDailyReader
CODE = 4755
CODE_str = str(CODE) + ".JP"
start = datetime(2014, 1, 1)
end = datetime(2023, 1, 31)
df_target = StooqDailyReader(CODE_str, start=start, end=end).read()
df_target = df_target.sort_values('Date')
df_target = pd.DataFrame(df_target).asfreq("D", method="ffill")
# 目的変数の作成(30日後に5 %以上上昇する時に1)
df_target["30days_after"] = df_target["Close"].shift(-30)
df_target['ratio'] = df_target['30days_after'] / df_target["Close"]
df_target['target'] = np.where(df_target['ratio'] > 1.1, 1, 0)
# 不要な行と列を削除
df_target = df_target.dropna(how='any')
df_target = df_target.drop(columns=["ratio","30days_after"])
# データの結合
df = pd.merge(df_target, df_market, how='left', left_index=True, right_index=True)
df = df.dropna(how='any')
# トレインとテストに分割
df_train = df[:"2021"]
df_test = df["2022":]
# 目的変数と説明変数に分割
X_train = df_train.drop("target", axis=1)
y_train = df_train["target"]
X_test = df_test.drop("target", axis=1)
y_test = df_test["target"]
# 学習
import lightgbm as lgb #LightGBM
model = lgb.LGBMClassifier() # モデルのインスタンスの作成
model.fit(X_train, y_train) # モデルの学習
# 予測値と実値との比較
df_result = pd.DataFrame()
df_result["Price"] = df_target["Close"]["2022-01-01":]
df_result["true"] = y_test
df_result["Pred"] = model.predict(X_test)



コメント